狼组Rom Hacker教程 —— Alan Yang(狼组)
http://www.chinaemu.net/zhuanti/Lvwu/hhzl.htm
简介:本文讲述如何对SFC游戏ROM进行汉化,并以实例带领读者破解一个Rom,最终实现部分文本对话的汉化。本文面向初学者,阅读本文仅需要预先了解16进制知识。
1. 汉化一个Rom的步骤
a. 找到游戏Rom中的码表(字符对照表);
b. 按照码表将Rom中的文本导出来,存成一个文件;
c. 翻译这些文本;
d. 找到Rom中的字库,并用中文字体替换;
e. 为中文字体再重新做一个码表;
f. 按照新码表将译文写回Rom中,并更新相应的指针表;
g. 测试。
下面我以七龙珠RPG(SF8047)为例,讲一下具体操作。
1.1 动手之前
在开始动手之前,你要先找到想汉化的游戏的ROM。注意,可不是随便从哪里down一个就行的!你要找到最完美的rom,这样才能保证不会因为Rom有问题,导致你的做了一半的工作白白浪费。具体说,就是要找经过GoodSnes和Romcenter校验过的Rom。
另外需要注意的是,要随时做好备份!原始的日文rom当然要做备份;对修改过的rom,我是每天作一次备份的。备份这个事,强调再多也不为过!
还有一个需要提醒的事,就是有些游戏同时有日文版rom和英文版rom。很多人以为用英文版的rom做汉化会简单一些。这是大错特错的!无论何时,记得一定要用日文版rom做汉化。这样做有以下几个原因:
1. 英文版的字库小,只有52个字母加一些标点;而要汉化一般需要1500-2000汉字,需要对字库做大幅扩容。日文版的rom一般都会带一些汉字,精打细算的话可能够用。
2. 英文版的字模小,一个字母也就8x12,而汉字一般是12x12到16x16大小,为了显示汉字,你又要asm hacking。
3. 英文版的对话远比日文长,为节省空间,一般做了压缩,这大大增加了破解难度。
2. 字库与码表
好,汉化任何游戏的第一步,都是要找到码表。什么是码表?请往下看。
2.0 一个例子
打开你的windows记事本,往里面写入“ABCDE你好”,然后保存为abc.txt。
现在的问题是,在这个文本文件里,记录了什么信息?是这几个字在屏幕上的图形吗?
现在,用UltraEdit(或其它你爱用的16进制编辑器)打开abc.txt,按一下"Ctrl-H",切换到16进制显示,你看到的应该是下面这样子:
0000000000h: 41 42 43 44 45 C4 E3 BA C3 ; ABCDE你好
左边的000000000h是地址,右边的"ABCDE你好"就是这个文件显示在屏幕上的样子;注意!中间的 41 42 43 44 45 C4 E3 BA C3,这才是真正记录在文件中的信息!
你可能看出来了,这绝不是这些字显示在屏幕上的图形。就算41-45是ABCDE的图形;“你好”两个字这么多笔划,也绝不可能用C4 E3 BA C3这几个字节就能完全记录下来。你是对的,这个文件里记录的只是字母(和汉字)的代码,并没有任何“怎么画这些字”的信息。那么“画字”的信息存在哪呢?打开你的C:\Windows\fonts目录看看,看见“宋体”、“楷体”等字体了吗?就是这里啊!
这说明了什么?说明PC机把如何显示文字的具体信息存在windows字库里;而我们平常写的文件(不管你是存成Word文件还是txt文件),里面只包含字的编码。
2.1 计算机是如何显示文字的
还是说刚才的abc.txt。你打开这个文件时,写字板程序先取出第一个字节41,然后,它去查一张对照表,这张表是这个样子的:
......
41 - A
42 - B
43 - C
44 - D
45 - E
......
从表中找到41对应字母A。现在计算机知道要在屏幕上显示"A"了,它就会从某个字库中(比如说宋体)去找字母A的字模(通俗的说就是如何画出宋体的A),并把字模显示在屏幕上。然后,取abc.txt的下一个字节42,以此类推。
那么,这张对照表就很重要了。它就是ASCII码表!所有PC上的公共标准。所以,你在自己机器上写的文件abc.txt,不会在朋友机器上显示成“KGTYU”,因为你们都用相同的ASCII码表!
2.2 SFC是怎样显示文字的
原理上基本和计算机一样。假设要显示的文本是"04 78 9A",码表是
......
04=孙
78=悟
9A=空
......
SFC先取出第一个字节04,查码表,是“孙”,再从字库里找到“孙”字的字模,显示在屏幕上;下一步取出78,查表是“悟”,显示字库里的相应字模,下一步...(算了,没稿费,不多写了,否则我打算写50个“下一步”:))
最后,“孙悟空”三个字就显示在屏幕上了。
2.3 SFC的码表
很遗憾,并不是所有的机器都使用ASCII码表,Machintosh就不用。而大多数游戏机,包括SFC,也都不用ASCII。不仅如此,各游戏开发小组根据自己的喜好和方便,随意安排每个字的编码,造成的结果就是:每一个Rom的码表都不相同!(标准的重要性在这里体现出来,要是有个统一标准,我们就不用费劲去找码表了,这也是为什么Microsoft总是力图让自己的产品成为标准)。
所以,Rom hacker的首要工作,就是找出码表。只有完成这步工作,才能按图索骥,顺利导出对话脚本、菜单、物品名等。
3. 寻找码表
3.1 最简单的情况-单字节码表
尽管每个SNES游戏用的码表都不一样,我们还是有规律可循的。对于英文字母,大家总是习惯按照字母表ABCDEFG....XYZ来排列顺序,SFC程序员也一样,所以假如"A"的编码是1,那么"B"就是2,"C"就是3,以此类推。
同样,日文假名也是按固定顺序排列的(五十音图),如下图。
1 あ a 2 い i 3 う u 4 え e 5 お o
6 か ka 7 き ki 8 く ku 9 け ke 10 こ ko
11 さ sa 12 し shi 13 す su 14 せ se 15 そ so
16 た ta 17 ち chi 18 つ tsu 19 て te 20 と to
21 な na 22 に ni 23 ぬ nu 24 ね ne 25 の no
26 は ha 27 ひ hi 28 ふ fu 29 へ he 30 ほ ho
31 ま ma 32 み mi 33 む mu 34 め me 35 も mo
36 や ya 37 ゆ yu 38 よ yo
39 ら ra 40 り ri 41 る ru 42 れ re 43 ろ ro
44 わ wa 45 を o
46 ん n
现在虽然我们不知道他们的编码,我们却知道,"A"和"B"的编码差1,"D"和"H"的编码差4。如果有个单词mana,那么字母与字母之间的差值肯定是
m a n a
\ / \ / \ /
11 -12 12
如果有工具能搜索差值,我们就能找到Rom中的文本。这种搜索叫“相对搜索”,(relative search)。我推荐的工具就叫Relativeful search,在狼组网站上可以下载。它既能输入英文搜索,又能输入数字搜索,还允许跳过几个字节输入。
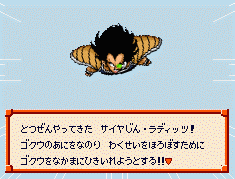
好,进入游戏,找一段文本,如左上图,抄下第一句话,根据上面的表格标上数字:
と つ ぜ ん ゃ っ て き た
20 18 ? 46 36 ? 19 7
现在打开Relative search:按"Open File"选择Rom,在"Values"后面填20,因为是十进制所以"Decimal",按"Add Value",20会出现在左下的"Values"列表里。如法炮制输入18,下一个值“ぜ”我们不知道,没关系,按一下"Skip value"跳过它。继续输入46和36。有五个就足够了。现在按下"Relativeful Search"按钮,等一下,右下的"Result"中会显示查到的结果。
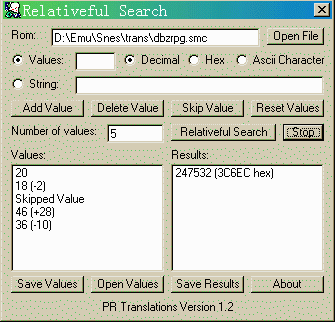
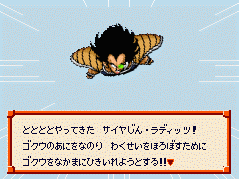
OK!找到一个。现在用UltraEdit(或你爱用的十六进制)编辑器,打开DBZrpg.smc。找到$03C6EC处,如图。这里是不是正确的地址呢?我们随便改几个值,再进游戏看看。

看有没有变化就知道了。把头四个字节"17 15 A8 31"全改成17,存盘,进入游戏。看看最上面的图,怎么样!头四个字全是“と”。说明我们找对了这句话的位置了!
现在我们知道17对应“と”(注意这里是十六进制,换成十进制是23)。由此可以推算出あ是04。好,可以把已知的部分码表做出来了。打开记事本,照这样写:
04=あ
05=い
06=う
07=え
.......
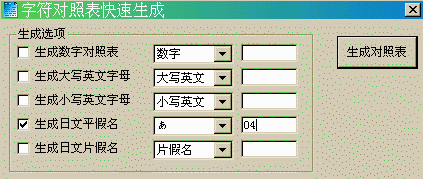
是否写起来很麻烦?这里推荐狼组hdw1978写的Table Maker,如图,选好“あ”和04,一按“生成对照表”马上就成了!是不是很方便。注意它有个小bug:假名"を"被遗漏了,你需要手动把它加入码表。这个工具最简单,狼组网站上还有其他更好的码表工具,大家可以自己试用。
你要是细心的话,应该还能看出,FF就是换行,FF FF是一段话结束。在码表中加一项:
FF=
其他的日文怎么办?太简单了,你只要在$03C6EC处随便乱写些数,再进游戏看看显示是什么不就成了?这些工作就留给你去做了。狼组有完整的龙珠RPG码表下载。看看跟你做的是不是一样?
对于含有大量汉字的rom来说,如果都一个个去试太麻烦了。一般来说,码表的顺序与字库的排列顺序是一致的,所以,如果你能找到游戏的字库,就可以直接把码表按顺序抄下来。
新手可能还有个问题:那些日文汉字都是输入法里找不到的,要怎样输入啊?最简单的就是用南极星里附带的输入法了。可以很快就找到你要输的日文汉字。如图:
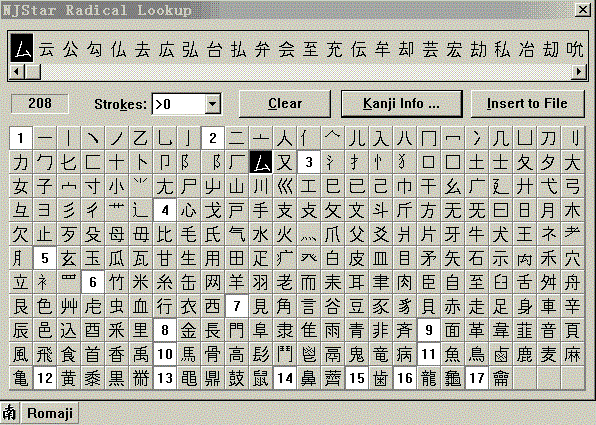
3.2 其它Rom及双字节码表
实际上任何Rom都是如此:只要它的文本没有被压缩,从假名入手都能找出码表。对于压缩的Rom,如果它允许你输入主角姓名,你可以起个名字存盘,再去Search存盘文件!你也可以用在输入界面不断地变换第一个字母,不要按确认,并配合FPE等进行低级搜索,找到缓冲区的确切地址。
对于有汉字的Rom,会更复杂一些。用一个字节来编码肯定不够,有些Rom就用到了双字节编码,还有的用到可变长编码。下面说一下火焰之纹章:多拉基亚776的例子:(主要注意它的格式)
我找到第一章一开始两个人的对话,在$0AA493处,格式如下:
00AA493h: 06 00 3A 78 00 07 00 3A 5B 00
---------- ------ -------- ------
第一个人 第1人头像 第二个人 第2人头像
06 09 4C 12 48 BB 0F 10 0A 5E 5F 09 29 0A D4
------ ----- -- -- -- ------ ---------- ----- -----
第1人说 ど ぅ だ 、 等待几秒 王 子 は 见
09 21 15 5C 1F 15 BE 02 08 07
----- -- -- -- -- -- -- ---- ------
つ か っ た お ? 换行 结束符 第2人说
776的文本很讨厌!不仅有正常的文字编码,还包含大量的控制符(例如切换说话的人物、头像)。
现在说码表,776码表是两个字节表示一个汉字或假名。日文平假名、片假名对应09 xx,汉字对应两个字节,从0A 10到0E 5F共1040个汉字。
双字节的表示方法:连续多个字都以09打头的话可以只写第一个09,省略后面字的09。其他段也一样。
例:
0A10=我
0A12=真
0A6E=棒
那么“我真棒”三个字的编码是:0A 10 12 6E
你可以试试改控制符,改变$0AA49D处的06为07,进入游戏,如何,原本该第一人说的话,现在由第二人说了吧!这里有两个人,编号06、07。头像也可以改。这种文本中夹杂控制符的rom是很常见的。
总之,要开动你的脑筋,不要拘泥于我写的这几种情况,用各种办法尝试,成功hack出码表的乐趣和成就感足以抵偿你花的时间!
有问题请到论坛提出。
4. 有关Rom的一些知识
在开始讲下一步之前,让我们先来了解一下ROM的结构,这有助于理解后面的内容。
一个ROM分为两部分:Header(文件头)和主体。Header是一个长$200字节的区域,在ROM的最前头,记录了一些ROM的相关信息。有些ROM甚至没有header。对于汉化,我们完全可以不关心header。而对于主体部分,那是我们的重头了,很遗憾的是,它没法再细分了。这里的内容存放,完全由该游戏的开发人员决定,所以一个rom一个样。
ROM的存储格式有很多,常见的有SMC、FIG、078等。可能你拿到的rom是好几个文件,那么你必须用snestool把他们合并成一个文件,最好是SMC格式的。
ROM的映射格式分为Low rom和High rom两种格式。具体的区别先不用管,你只要知道如何确定一个rom是哪种格式。我们用一个叫ucon的小程序来帮忙,它也可以用来转换rom格式。在DOS命令行下执行
ucon dbzrpg.smc,得到这样的结果:
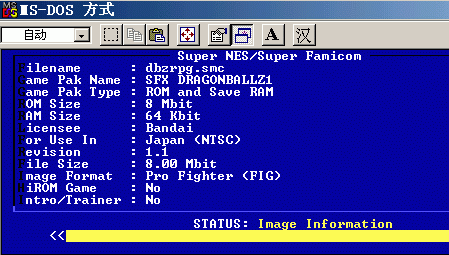
如图,在HiRom Game一项写的是No,那么这就是Low Rom。至于有没有header可以计算出来:例如龙珠是8M的rom,大小应该是1024×1024=1048576(注意它是8M bit,相当于1M byte),但是查看一下文件属性,大小是1049088,多了512字节。这512字节就是header,正好是十六进制的$200。
所以,我们知道了龙珠RPG是有header的,Low rom格式。
5. 指针表与文本块
铛铛铛铛铛铛,继续理论课!不要说我跟唐僧似的,可一定要用心看明白啊!
假如我要开发一个游戏,其中肯定有好多对话。这些对话文本怎么存储呢?一种方法是哪里用到一句对话了,就把一句话写在哪里,对话之间插入很多的控制符,甚至程序。这就是“漂浮”的文本。可是这样很麻烦,如果后来对话脚本要修改,句子变长了,就要影响后面的程序。这样的Rom,像火焰纹章系列、浪漫沙加系列都是,汉化起来很麻烦。
更好的方法是,把所有对话(文本)都放在一起,对话与对话之间用一个特定的结束符分开。然后,再做一张表,表中每一项都指向一段话的第一个字。这张表就叫指针表(Pointer Table),那一大堆文本叫做文本块(Text Block)。举例如下:
指针表:
00 60
0F 60
1D 60
2F 60
3A 60
文本块:
地址 文本
6000-600F: This is a dog.|T
6010-601F: hat's a pen.|Do
6020-602F: you play game?|C
6030-603F: ertainly!|What's
解释:我先说明一下,在汇编及16进制中,两个以上字节的东东,最前面的字节叫高位,后面的叫低位。比如$34AB,34是高位,AB是低位。在Rom里,它是这样存放的:先低位后高位。所以$34AB在Rom里存成“AB 34”。
文本块地址是16进制的,从6000-600F一共有16个字节,即一行有16个字符。“|”是结束符,标志一句话结束。指针表中每一项由两个字节组成。先看第一项,00 60,实际上是指向地址$6000,正是"This is a dog."这句话的开头。下一项0F 60,指向地址$600F,正是"That's a pen."的开头。
采用这种方法存储,最大的优点就是,随时可以改对话文本的长度!只要改完后,把指针表相应的指针指向正确的位置,根本不用改动程序!这样的rom我们汉化起来也比较方便,因为可以写程序来自动导入导出对话脚本。
6. 指针表、文本块、字库与码表的协作关系
先仔细看看这张图,能看明白吗?这是如何显示一个字的完整流程。
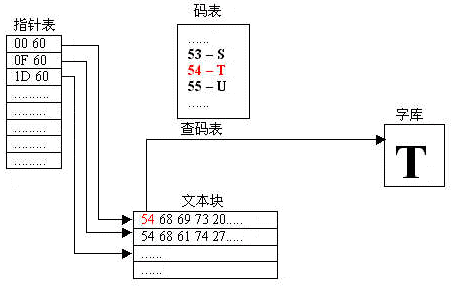
如图,假设程序中要显示一句话,这句话是文本块中的第一句。程序会调用显示子程序来显示这句话。开始运行。首先,它检查传给它的参数“1”,这是指要显示文本块中的第一句话。查指针表,第一项指向$6000,OK,从$6000地址取出一个字节$54,查码表,得知$54表示字母T,再从字库中找到字母T的字模,并显示出来。
然后,从$6001取出第二字节$68,重复上述操作。一直到$600E,取出的值是$FF,这是结束符标记,显示子程序返回结束。此时,第一句话已经显示在屏幕上了:“This is a dog.”
明白了?当程序中要显示文本时,只要调用显示子程序,并告诉它要显示哪一句话,显示字程序就会把对应的话显示出来。
7. 寻找指针表
现在我们要找指针表了。还是用龙珠Rom,还记得这个Rom有文件头,是Low-rom吧。上一讲我们找到第一句话的开始地址为$03C6EC,减文件头$200后是$03C4EC,去掉高位03并交换,得到Rom中的存放格式为EC C4。这就是找指针表时的计算方法。
在UltraEdit中打开rom,向上搜索这个值,马上找到一个地址$0394A2。(此处如有疑问请参见看我翻译的“汉化高级教程”一文)
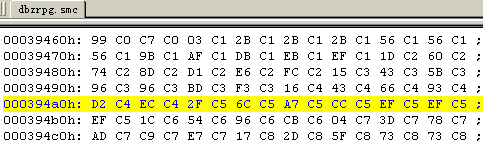
观察这个地址附近的数值,发现是有规律的,每两个字节一组,都指向Cxxx附近。肯定就是这里。把ECC4改成第二句话的地址03C5(指向$03C703),进入游戏看看(如图),哈哈!拉蒂兹只说后两句话了。
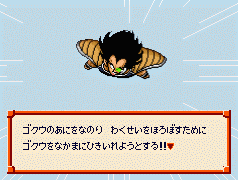
这里就是指针表没错!通过指针表,可以很容易地找到每段文本的开始。指针表很有用处;如果你会写程序,它可以大大方便导出和导入过程。将来所有中文文本都插入后,还要更新指针表,重新指向各段中文文本的首地址。
8. 导出脚本对话(Dump Script)
现在,你只需要导出文本,交给一个翻译去翻,兴奋吧?我们来看看怎样导出脚本。
DOS下最常用的工具之一是Thingy。早期的英化中,好多老外专门用它,所以它支持的码表格式也就成了标准。当然现在有很多工具已经超过它了,但它仍然不能不提。

执行Thingy,它会问你Rom名字和码表名字,它支持两个码表同时使用,第二个是可选的。进入Thingy后,随便翻翻页,你发现,右侧显示的已经是日文了!把光标停在文本块开始处,按D,回车;翻页到文本块结束,再按D,Thingy会提示你给导出的文件起个名字。写上名字后,这一块文本就导出来了。
其实有人专门编了工具来进行导入导出。Script-extractor和Script-Insertor就不错,用起来比Thingy方便多了。导出的文本就像下面:
「それともじっくりとあそんで
ころそうか?へへ……いくぜ!」
「おとうさん!ピッコロさんが…
ピッコロさんしんじゃった-!」
「すまん……おそかったか…!
ゆるさんぞ!オメエら--!!」
じめんからカイブツが?
「なうだ!!きさまらこいつらと
1ぴきずつたたかってみんか!!」
「まさかこんなクズなもに……
こうなったらカカロットの
ガキをみちづれにしてやるぜ!!」
再稍微处理一下就很不错了,下面就是翻译的工作了。
狼组汉化专区还有很多工具都可以导入导出,大家可以选自己最方便的使用。
对于有编程能力的rom hacker,最好是自己写程序导出。我习惯是把整个rom都导出来,再手工整理去掉垃圾。下面是我导出776对话用的VB源程序核心部分,其实很简单的,大家可以参考。完整程序在专区。
简单说明:MB(a,b)数组包含当前的所有码表,count是计数器,每3句话显示一次地址。每次从rom里取一个字节放在d里,再根据码表译成文字。hz代表码表第几段,hz=0时是假名和字母(即09xx)。
For i = start To endp
Get #2, i, d
If d = 0 Then
i = i + 1
Get #2, i, d
If d = &H11 Then
hz = 0
ElseIf d = &H12 Then
hz = 1
ElseIf d = &H13 Then
hz = 2
ElseIf d = &H14 Then
hz = 3
Else
Print #1, str
count = count + 1
If count = 3 Then
count = 0
str= "<$" & Hex(i + 1) & ">"
Print #1, " "
Print #1, str
Bar1.Value =CInt((i - start) / 1000)
End If
hz = 0
str = ""
End If
Else
str = str & Mb(hz, d)
End If
Next
好,今天的课就到这里。学完这课后,大家应该可以导出对话文本,开始找翻译了!顺便澄清一个错误观念:汉化不需要你会日文,因为我们要有分工的嘛。见到有些朋友在论坛说“我先学好日文吧”,其实根本没必要的,像我就完全不懂日文。有问题请到论坛提出。
9. 查找字库
好,现在要做的,是最有意思的部分!
先来个名词解释:TILE(图块)-是指8x8的一小块图。SFC中的所有图形都是用8x8的小块图形拼成的,有点像马赛克。这一个8x8的小图块就叫tile。它是最小的图形单位,不可再分的。对话汉字同样也是用tile拼成的。一般游戏用的文字,从12x12到16x16大小的都有,用4个tile拼成。
怎么能看到tile呢?我们用一类叫精灵编辑器的工具(精灵是指用tile拼好的人物或头像)。其中最好用的是Tile Layer Pro(TLP),网站上有下载。用TLP打开龙珠的rom,显示是这样的:
选择“View”“Format”,然后选择“Gameboy”模式。像这样:
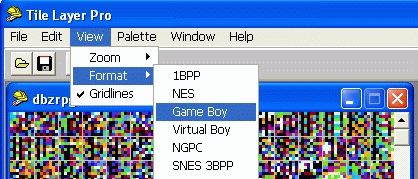
为什么要选GB模式呢?对于SFC的游戏,字库一般都是2bpp格式(关于1bpp,2bpp的含义,感兴趣的请看站上其他文章)。GB模式恰好就是按2bpp格式显示tile。
好,现在睁大眼睛,按“Page Down”翻页,仔细看有没有像文字的东西!如果找到了,那就是字库。
但是……好像找不到啊~!答对了,龙珠RPG的字库是压缩的!
(打死他,竟敢欺骗读者!......Alan被读者攻击,HP减少30点)
啊……对不起,事先没仔细看,就选了这个rom,谁知字库是压缩的。这也告诉我们,汉化的第一步不是找码表,而是先看能不能找到字库,再找码表。除非你会asm hack,否则,遇到压缩的字库,你最好就换个rom下手吧。从现在开始,我以776为例讲解字库替换和汉化对话。请回忆一下第一课讲过的776码表。
10. 多拉基亚776的字库
776的码表站上有下载,可以下载回来做为参考。我再简单说明一下:
776采用双字节编码,如0A20=神。在这个编码里,第一字节0A,我们把它叫做段号,第二字节20才是字的实际编号。776共有09xx,0Axx,0Bxx,0Cxx,0Dxx,0Exx六段。
在rom中,系统会尽量节省空间。对于每个字,如果它的段号和前一个字相同,就可以省略段号,只用一个字节。
如:09 A0 23 E1 0B 45 21 09 61 0A 8B
上面这行对话,黑体字代表段号,后面的是1字节的编码。如头四个字节,实际代表了3个字符:09A0 0923 09E1。其后是0B 45 21,系统将它解释为2个字符0B45和0B21,以此类推。
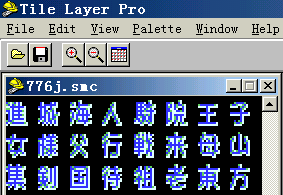
好,现在用TLP打开776的日文rom,换到GB模式,往下翻吧!很快就可以看到大段汉字了,这就是字库!(左下图)
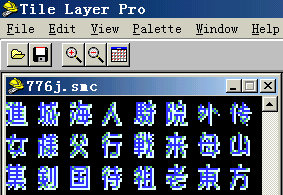
现在我们把字库里的“王子”二字改成“外传”看看:
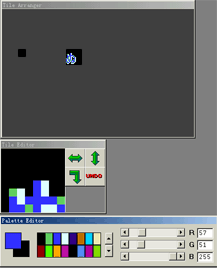
改字要用到TLP的编辑功能了。先点击要改的tile,在中间编辑框里就可以编辑了。下方是调色板,776里用到了四种颜色:蓝绿白黑。其中蓝色是重要的,绿白二色是阴影。用鼠标慢慢“画”字吧,相信很快你就能掌握的。右上方的图是改完的样子。(画字模可以参考专区其他文章)
改完后存盘,然后我们进游戏看看有什么变化:
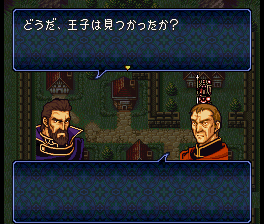
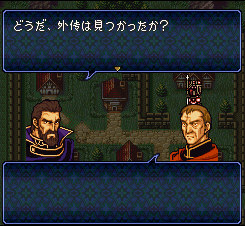
左图是原始的样子,右图是改完后的样子,看看:“王子”变成“外传”了。
这就是修改字模!以后,我们会把所有的日文汉字及假名都改成中文字模的。
11. 制作中文对照表
太简单了。先打开一个空的文件,把“王子”二字的编码从日文码表拷贝过来:
0A5E=王
0A5F=子
然后把“王子”二字改成“外传”:
0A5E=外
0A5F=传
好,现在把这个文件存盘,起名叫776c.tbl。这就是我们的中文对照表!以后,随着做汉字字模,随时往里添加新的编码就行了。
12. 将中文译文写回Rom中
(假设你已经把所有字模都做好了)
我们还是以776第一章的第一句话为例:(如果你的ROM有header,地址是00AA69E)
00AA49E: 09 4C 12 48 BB 0F 10 0A 5E 5F 09 29 0A D4 09 21 15 5C 1F 15 BE
どぅだ、王子は见つかったお? 瓦斯曼,发现王子了吗?
根据我们的中文码表,查出每个字的编码,再根据776的特点,把相同的段号省略,结果应该是这样的:
00AA49E: 0B A6 0A 69 0B 85 09 BB 0B 43 44 0A 83 63 47 0B 45 09 BE
用你爱用的16进制编辑器写入rom,存盘,再进入游戏去看看,怎么样!这句话已经汉化了吧!
可是,汉化后比日文文本少了两个字节,怎么办?没关系,汉化下一句话时,紧接着这一句汉化就行了。如果汉化后的字节比日文的多了,也不用怕,按顺序往下汉化就行,只要最后一句话正好在原来的日文编码位置上结束就没问题。
776是不用考虑指针表的问题的;但是有些游戏需要指针表。那么,在汉化完后,也要把指针表对应的指针,改成指向中文对话的起始位置。
13. 加速汉化进程
如果这前面的东西你都看懂了,实际上你已经学会了汉化需要的技能了,祝贺你,找个游戏rom练练手吧!
但是,如果你真的照前面我讲的去做,一定会累死的。工作量实在太大了。怎样能加速汉化进程呢?当然要利用各种工具啦!
A. 首先,画字模很烦,我们完全可以用工具来做!Edison的CharEdit可以选择任意的字体字号,写入rom中,很方便的。但是它只能写入2bpp格式的字模。就算画字模也可以加速,狼组Dark01首先发明的结合Photoshop的画字模方法非常实用。如果你会一点编程,建议你去研究一下1bpp、2bpp等字模存储格式,再看看“任意字体字模生成器”这个程序,然后你就可以自己写一个程序,一次把所有字模都写入rom中啦!狼组现在基本不需要做字模的人了,因为我们对标准大小的字体一律用程序写入。
B. 推荐狼组的“汉化辅助工具”,这是个自动把中文/日文翻译成代码的工具,还可以检查哪些汉字还没做字模。第一次使用时要设置好中日文的对照表。

好,Rom hacker的课程到这里就全部结束了。希望你也能汉化成自己喜欢的游戏!记住:汉化游戏,最最需要的,不是技术,而是耐心和坚持。祝你成功!